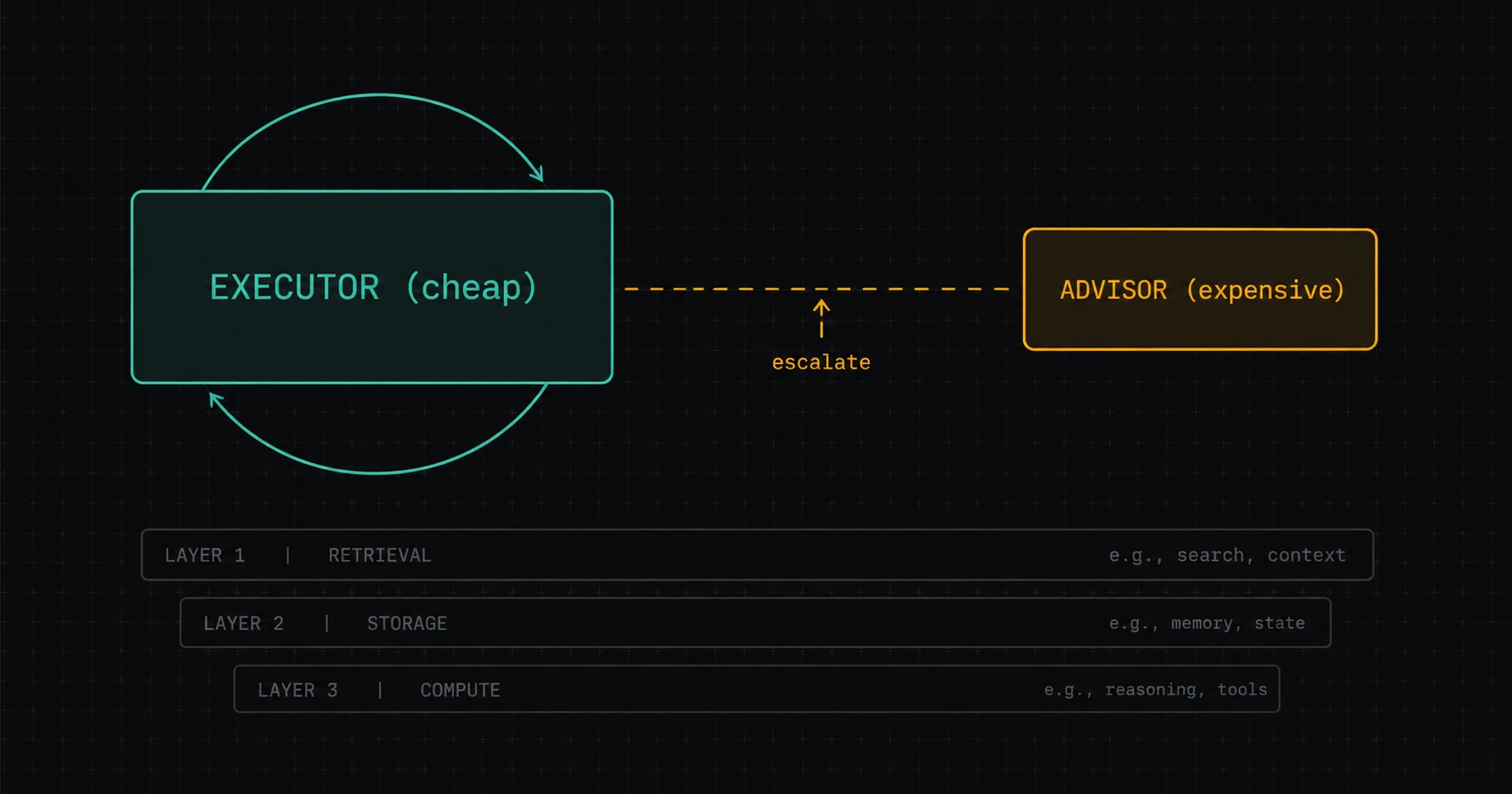
Agent Architecture Is a Compute Allocation Problem: The Advisor Strategy, Cost-Curve Frame Recursed
Anthropic named the advisor strategy in April. Tobi Lutke made it viral in May with Qwen plus GPT-5.5. Stanford's HazyResearch formalized the same shape earlier. One cost-curve frame unifies all three: a cheap executor runs the loop, an expensive advisor weighs in only at hard decisions. The third recursion.
Table of Contents
In April 2026, Anthropic published a blog post called “The advisor strategy: Give agents an intelligence boost”, naming a pattern they had been A/B-testing in production: a cheaper model runs the agent loop end-to-end, an expensive model is consulted only when the cheap one hits a decision it can’t solve. They reported concrete numbers — Haiku + Opus advisor on BrowseComp at 41.2% (Haiku alone: 19.7%) at 15% of the cost of running Sonnet through the whole task.
On May 18, 2026, Tobi Lutke (CEO of Shopify) tweeted about an autoresearch setup that did exactly this: Qwen 3.6 27B running locally on an RTX 6000, with a small “advisor extension” that periodically calls GPT-5.5 for direction. 13,000 impressions, 2,400 likes, dozens of replies from engineers reproducing the pattern or building open-source implementations within hours.
Underneath both of those, Stanford HazyResearch’s Minions paper — published months earlier — had abstracted the same pattern into a compressor-predictor framework: a small local model distills raw context into compact text that a larger remote model then reasons over. They reported their Deep Research system recovering 99% of frontier-model accuracy at 26% of the API cost.
Three independent threads converging on the same architecture in roughly the same six-month window. That convergence is the story.
This post argues something specific about it: the advisor strategy isn’t a new pattern invented for LLMs. It’s the third recursion of the cost-curve frame from earlier in this mini-series — the same idea that argued grep beats RAG for code retrieval, and that argued SQLite + FTS5 beats a vector DB for the symbol-graph storage that grep-replacement tools (CodeGraph) need. Applied at the model-orchestration layer, the frame produces the advisor strategy. The strategy is the architecture; the frame is why.
tl;dr — Anthropic, Tobi Lutke, and HazyResearch independently shipped (or described) the same agent pattern in early 2026: a cheap model runs the loop, an expensive model is consulted only for decisions. The convergence is evidence the pattern is correct; the reason it’s correct is the cost-curve frame from this series’ first post, applied at the model-choice layer instead of the retrieval-architecture layer. Piece B argued grep+loop beats RAG because build/maintain cost dominates per-query cost below a crossover. The advisor strategy argues the same shape for tokens: cheap-model executor cost dominates expensive-model advisor cost for the bulk of low-value operations (reading context, format conversion, retries), so expensive-model tokens should be spent only at high-value decision points. Same frame, third layer.
The post does three things: (1) reports the three converging threads with what each contributed; (2) makes the cost-curve recursion argument explicitly — L1 retrieval, L2 storage, L3 model orchestration; (3) maps the gotchas the hype skips (data egress on handoff, eval difficulty, handoff-contract design as actual engineering, hardware realism). The mini-series concludes here, five posts in, with cost-curve frame as a meta-design law across three layers of agent architecture.
Three convergent threads, in the order they shipped
The convergence matters more than any single thread. Each was independent; each shipped within a six-month window of the others; each describes the same architecture from a different vantage. That’s how you know the pattern is real and not just one team’s design preference.
Anthropic’s official advisor strategy (2026-04-09)
The Anthropic engineering blog “The advisor strategy: Give agents an intelligence boost” defines the pattern as a productized engineering primitive:
“Sonnet or Haiku runs the task end-to-end as the executor… When the executor hits a decision it can’t reasonably solve, it consults Opus for guidance as the advisor.”
“The advisor never calls tools or produces user-facing output, and only provides guidance to the executor.”
The reported empirical numbers:
| Configuration | Benchmark | Score | Cost (relative to Sonnet end-to-end) |
|---|---|---|---|
| Sonnet alone (no advisor) | SWE-bench Multilingual | (baseline) | 1.00× |
| Sonnet + Opus advisor | SWE-bench Multilingual | exceeds baseline | 0.88× (−11.9%) |
| Haiku alone | BrowseComp | 19.7% | (baseline) |
| Haiku + Opus advisor | BrowseComp | 41.2% | 0.15× of Sonnet-end-to-end |
Two observations on the numbers. First: the Sonnet + Opus combination outperforms Sonnet alone while also being cheaper — that’s not a one-axis trade, that’s a Pareto improvement. Second: the Haiku + Opus combination doubles Haiku’s standalone score while costing 15% of Sonnet’s. That’s the compound gain — better and cheaper at the same time.
A specific detail in the blog: the advisor’s outputs are typically 400–700 tokens — a short plan, not a full solution. That’s the design saying out loud what the cost curve implies — the advisor exists to redirect, not to do work.
Tobi Lutke’s personal experiment (2026-05-18)
Tobi Lutke (CEO of Shopify) posted on X:
“I’ve had very good results running autoresearch with local qwen 3.6 26b model as long as I had a simple vibed pi ‘advisor’ extension that allowed it to periodically ask GPT 5.5 for ideas. I think this direction has a lot of merit.”
Tobi’s setup is the open-source mirror of Anthropic’s productized pattern, with two architectural variants:
- Locality: the executor runs on his own hardware (Qwen 3.6 27B on an RTX 6000), not on Anthropic’s API. Local-first by default.
- Frontier model choice: the advisor is GPT-5.5 (OpenAI), not Opus (Anthropic). The pattern is model-agnostic on the advisor side.
The hardware caveat is real and worth naming: RTX 6000 is professional-grade, not consumer hardware. 27B-dense models with autoresearch-length contexts aren’t laptop workloads. The pattern is reproducible at the architecture level on commodity infrastructure; the specific setup Tobi shows takes real investment.
Within hours of Tobi’s tweet, developer Rob Zolkos published pi-lifeline — an open-source escalation extension explicitly inspired by the tweet, with reasonable defaults: at least 5 rounds before the first advisor call, automatic escalation after 3 consecutive failures, plateau-detection after 6 rounds, max 10 advisor calls per session, default advisor model GPT-5.5. That’s engineering of the handoff contract — not a one-line config — and we’ll come back to it later.
Stanford HazyResearch Minions (2025–2026 publication window)
Linked from a reply on Tobi’s tweet — Dan Biderman pointing at HazyResearch’s Minions paper (arXiv 2512.21720), which abstracts the pattern into a compressor-predictor framework:
“smaller ‘compressor’ LMs (that can even run locally) distill raw context into compact text that is then consumed by larger ‘predictor’ LMs.”
The Minions paper’s specific numerical contribution: in their Deep Research system, a local 3B-parameter compressor recovers 99% of frontier-model accuracy at 26% of the API cost. That’s the academic version of the same architecture, with empirical bounds.
Three things HazyResearch’s framing adds beyond Anthropic’s product blog:
- The compressor doesn’t have to be 27B — even 3B works for context distillation, depending on the task. The lower the compressor can go, the more local you can run.
- The cost-recovery curve has a specific shape — 99% accuracy at 26% cost isn’t linear. It’s the same Pareto improvement Anthropic reported in product form: better and cheaper, not just cheaper.
- The general framing is “compress then decide” — a slightly broader frame than “executor + advisor” because it includes the case where the compressor runs once at the start and the predictor runs once at the end, with no escalation loop. The advisor strategy is a streaming version of compress-then-decide where compression happens iteratively.
Why three independent confirmations matter
Each thread is from a different vantage:
- Anthropic: product engineering. Owns the model, designed the workload, reports field metrics.
- Tobi Lutke: individual practitioner. Different model providers (Qwen + GPT-5.5), different hosting (local + cloud), different workload (autoresearch, not coding benchmarks). Reproduced the pattern without coordinating with Anthropic.
- HazyResearch: academic research. Different framing (compressor-predictor), different time horizon (paper preceded Anthropic’s blog), different cost-quality measurement methodology.
When three independent vantages produce the same architectural answer, the design is robust to who happens to be sponsoring the work. That’s the convergence-as-evidence argument — the pattern is real and not just downstream of one organization’s preferences.
The interesting question now isn’t whether the pattern works (the convergence proves it does). It’s why it works — and that question has a clean answer from earlier in this mini-series.
The cost-curve recursion: same frame, third layer
Piece B (the first post in this series) argued that LLM-driven code retrieval sits on a cost curve: index-based approaches pay high build cost + super-linear maintain cost, tool-loop approaches pay per-query cost only. Below a crossover point — which sits well above most projects’ size — tool-loops win. Above it, indexes pay back.
That argument generalizes. Applied to other agent-architecture decisions, the same frame keeps producing the right call.
Layer 1 — Retrieval architecture (Piece B)
| Tool-loop (grep + LLM iteration) | Index (vector RAG) | |
|---|---|---|
| Build cost | 0 | super-linear in repo size |
| Maintain cost | 0 | super-linear in churn × structural complexity |
| Per-query cost | N tool-call round-trips | one vector search + LLM reasoning |
| Win condition | Below crossover | Above crossover |
Conclusion: for most repos, build/maintain cost dominates per-query savings, so tool-loop wins. Anthropic chose grep+Glob+Read for Claude Code, not an index.
Layer 2 — Index storage (C2, the first-principles read of CodeGraph)
When you do cross the curve and need an index — CodeGraph’s territory — the next decision is which storage layer to use.
| FTS5 + SQLite (CodeGraph) | Vector DB (Chroma / Pinecone) | |
|---|---|---|
| Build cost | linear in source size, parse-only | super-linear (chunk + embed every file) |
| Maintain cost | low (file watcher + incremental parse) | super-linear (re-embed on change, handle cross-chunk refs) |
| Per-query cost | exact lookup, sub-millisecond | ANN search + rerank + LLM call |
| Win condition | Exact-lookup workload | Semantic-similarity workload |
CodeGraph’s queries are exact lookups (find symbol X, trace A→B, callers of Y), so FTS5 wins. Same frame as Layer 1: pay only the costs your workload demands.
Layer 3 — Model orchestration (this post — the advisor strategy)
Apply the same frame to token allocation across models.
| Cheap-only (Haiku alone, Qwen alone) | Expensive-only (Sonnet/Opus end-to-end) | Executor + Advisor | |
|---|---|---|---|
| Per-token cost on bulk operations | low | high | low (cheap executor handles 90%+ of tokens) |
| Per-token cost on key decisions | low (but quality suffers) | high (and quality matches) | high (advisor only for decision tokens, ~400–700 tokens per call) |
| Aggregate task cost | low if quality holds | high regardless | low (most tokens are cheap; decision tokens compound from the expensive model’s quality) |
| Aggregate task quality | depends on whether decisions are within cheap model’s capability | full | high (cheap executor + expensive decisions ≈ expensive end-to-end, sometimes better) |
| Win condition | Tasks where cheap model alone is adequate | Tasks where any decision could be critical | Tasks where most operations are routine but some decisions are hard |
Most agent tasks fit the last column. The advisor strategy wins for the same structural reason grep+loop wins at Layer 1: the cost of the “bulk” operations dominates the cost of the “decision” operations, so the architecture should put the cheap tool on the bulk path and reserve the expensive tool for the decision path.
Cost-curve as a meta-design frame
Stating the generalization explicitly: whenever an architecture has a “many low-value operations + few high-value operations” structure, applying expensive tools uniformly across both pays the high cost for the low-value operations too. The right design separates the two paths and uses cheap-but-good-enough tools on the bulk path.
This is the design rule the cost-curve frame produces at every layer it’s been applied to in this series. It’s not specific to LLMs — the database community calls this “use the cheapest index that satisfies the query class”; the systems community calls this “tiered storage”; the chip design community calls this “the memory hierarchy”. The LLM-engineering version is the advisor strategy plus its retrieval-architecture cousins.
This is the meta-design law the five posts in this series argue for. The argument’s strength comes from the convergence — three independent recursions of the same frame producing the right architecture each time. That’s not coincidence; it’s the frame doing its job.
What this validates from Piece B’s source-code analysis
Piece B’s analysis of Claude Code’s source code reported a specific finding: the Explore subagent runs on Haiku for non-ant builds (external users), not on Sonnet or Opus. The reasoning section of Piece B observed:
“Explore runs on Haiku for external users. Not the main reasoning model. Exploration is a cheap-tokens job — there’s no creative reasoning happening, just iterate-and-filter — and Anthropic uses a fast, small, cheap model for it. The main agent gets the expensive model when it gets the summary back. This is the staffing analogue: junior associate does the deposition review, senior partner reads the brief.”
That’s the advisor strategy, visible directly in Claude Code’s source. Piece B analyzed the mechanism rather than the branding, so it didn’t use Anthropic’s later label — but it’s the same architecture. The point isn’t priority over the announcement; it’s that the pattern was already running in shipped code, observable by anyone reading the source rather than waiting for a launch post to name it.
There’s a useful takeaway here for reading any AI engineering work: the source code is ahead of the blog posts. The blog post explains and packages what’s been running in production. Reading the source is one of the cheapest ways to see where the foundational labs are betting, because the explainer post usually describes what was already shipping in the code months earlier.
The advisor strategy is one of three patterns Piece B’s source-code reading surfaced in this category. The other two are worth flagging because they suggest the next blog posts to expect:
- The Fork-subagent architecture (visible behind the
isForkSubagentEnabled()flag) — a different model-orchestration shape where the cheap and expensive halves share a context (and prompt cache) rather than separating cleanly. If Anthropic productizes this, expect a blog post titled something like “Fork: shared-context model collaboration” in the next 1–3 quarters. - The
tengu_amber_stoatGrowthBook flag — gating Explore vs. no-Explore as a deeper architectural test. If Anthropic concludes the cheap-executor-as-separate-subagent pattern doesn’t pay off, the next blog post is about why the advisor strategy works in some shapes and not others.
The general point: reading the source code and observing the patterns lets you write the analysis before the productized name arrives. When the name does arrive, your analysis is what frames it. This is the time-shift advantage that source-leaning engineering writing has over pure-press-release-paraphrase content. It’s why this series’ posts have been holding up under fresh data — the frame was built from the same source the announcements describe, so new announcements tend to confirm it rather than surprise it.
The gotchas the hype skips
The convergence between Tobi, Anthropic, and HazyResearch is real and the pattern is solid. But there are four gotchas the hype reliably skips that any production implementation has to address.
1. Data egress on handoff
The local-first appeal of Tobi’s setup (executor runs on your own GPU) hides a subtle leak. Every time the executor escalates to the cloud-hosted advisor, some subset of the executor’s context goes to the advisor’s hosting environment. What gets sent is the executor’s choice; once it’s sent, it’s no longer local.
Commenter @DarshanSays on Tobi’s tweet flagged this explicitly: “local + remote advisor mode quietly creates a data egress channel.” The pattern gives you cost control and partial privacy — most of your raw data stays local — but not full privacy. For workloads on sensitive data (security tooling, healthcare records, internal source code), the advisor’s contract is now an exfiltration vector if it’s poorly designed.
The mitigations are real engineering, not config:
- Redaction layer between executor and advisor — strip identifiers, replace specific names with placeholders, summarize before sending
- Hand-off contract documentation — explicit specification of what gets sent and what’s excluded
- Audit logging — every advisor call is logged with what was sent, so it’s reviewable
2. Eval is structurally harder than it looks
The benchmark numbers Anthropic and HazyResearch reported are real but represent specific tasks. For your task, you don’t know whether the advisor strategy pays off without measuring on your workload. And measuring is harder than for a single-model agent because:
- The executor’s failure modes and the advisor’s failure modes interact — bad escalation can make the advisor strategy worse than executor-alone
- The right escalation policy is task-dependent — too eager wastes advisor cost, too reluctant leaves executor stuck
- Quality differences from advisor strategy show up not just in pass/fail but in answer completeness (similar to the Q4 refactor-impact analysis in C1’s benchmark) and modal status (is the answer correctly hedged vs. confidently wrong? — see Piece A’s modality-flattening discussion)
A serious eval setup for the advisor strategy needs:
- Baseline: executor alone, expensive model alone, advisor-strategy variant — three arms, not two
- Multiple escalation policies (eager / moderate / conservative) tested separately
- Both correctness and completeness scoring, not just pass/fail
- Statistical reporting (variance across runs, not just averages)
This is more work than benchmarking a single model. It’s the kind of thing teams skip because the “single number” benchmarks already look good — but the single numbers can hide that the policy matters more than the configuration.
3. Hand-off contract design is real engineering
The advisor strategy’s “magic” is the executor calling the advisor at the right moments with the right context and getting back actionable guidance. Every clause in that sentence hides an engineering decision:
- When to escalate — after N consecutive failures? When confidence (measured how?) drops below threshold? After K rounds of no progress?
- What context to send — the full executor working state? A compressed summary? The recent N actions and outcomes?
- How to format the advisor’s response — free-form text? Structured JSON? Action recommendations vs. analysis?
- How the executor integrates the advice — adopt verbatim? Treat as a hint? Use to seed the next attempt?
Pi-lifeline’s defaults (5 rounds before first advisor call, 3 consecutive failures auto-escalates, plateau-detection at 6 rounds, max 10 advisor calls per session) are one set of choices. They’re reasonable but not universal. The right choices depend on the task; getting them wrong destroys the strategy’s value even when the underlying models are good.
4. Hardware realism
Tobi runs Qwen 3.6 27B on an RTX 6000 (NVIDIA professional-grade). The published benchmarks from Anthropic and HazyResearch use specific model versions and infrastructure. The architecture is reproducible on commodity infrastructure; the specific results are not.
For practitioners considering the pattern:
- Local executor (Qwen-class 27B+ dense model with long-context autoresearch loads) realistically needs RTX 6000 or A100-class hardware. Consumer cards (RTX 4090, RTX 5090) work for shorter contexts but throughput drops on long sessions.
- Quantized GGUF versions (e.g., Unsloth’s quantizations) help with VRAM but not throughput — same hardware needed for the same wall-clock latency
- Hybrid cloud-first executor (Haiku/Sonnet on Anthropic API) avoids the hardware question but loses the local-data-leaves-only-on-escalation property
The realistic deployment shape depends on what you’re trying to optimize. Cost-only: cheap cloud executor + expensive cloud advisor. Privacy-first: local executor + cloud advisor with redaction. Speed-first: cloud executor with low advisor latency. The advisor-strategy architecture is the constant; the implementation varies by which axis dominates your requirements.
Engineering implementation: where to actually start
If you’re considering the advisor strategy on a real workload, the cheapest first step is to measure your single-model agent’s token distribution — what percentage of tokens go to context reading vs. format conversion vs. actual reasoning. If 70%+ of tokens go to bulk operations, the advisor strategy has a big payoff potential. If the distribution is flatter, payoff is smaller and the engineering overhead may not be worth it.
Once you’ve decided to try the pattern:
- Pick an executor model — start with the cheapest model that can complete most of your tasks reliably. For coding agents, Haiku is the obvious starting point; for autoresearch, Qwen 3.6 27B (or whatever local 27B-class model fits your hardware).
- Pick an advisor model — Opus for Anthropic-stack workloads, GPT-5.5 for OpenAI-stack, whichever frontier model you trust on the task class.
- Design escalation triggers — start with pi-lifeline’s defaults as baseline, tune based on observed executor failure patterns. The right number depends on your task.
- Design the hand-off contract — what context goes to the advisor, what format the advisor returns. Start minimal (recent N actions + current goal), expand if advisor quality is poor.
- Implement redaction — if your data is sensitive, the redaction layer is non-negotiable. If not, you can skip it for v0 but document the egress.
- Measure — three-arm eval (executor alone, advisor strategy, expensive alone), correctness + completeness scoring, variance across runs.
- Iterate on the policy, not the models — when the strategy underperforms, the fix is usually in escalation timing or hand-off content, not in swapping models.
The pattern works. The engineering around it determines whether it works for you.
Closing — the mini-series, completed
This is the fifth and final post in a series on agent retrieval, memory, and orchestration architectures:
- Agent Retrieval Is a Cost Curve Problem (2026-05-25) — Layer 1: retrieval architecture. Why grep+loop beats RAG for code, and why the cost curve says so.
- Agent Memory Is a Cache Coherence Problem (2026-05-28) — the cache-coherence frame for lossy auto-capture AI memory tools, with the modality-flattening failure mode mapped out.
- I Tested CodeGraph on Hono. The Tool-Call Savings Reproduce — the Cost Savings Don’t. (2026-06-01) — empirical: when the cost curve is crossed (mid-size repo, architectural questions, static-typed language), CodeGraph crosses it cheaply.
- Agent Retrieval Above the Crossover: A First-Principles Read of CodeGraph (2026-06-08) — Layer 2: index storage. Why SQLite + FTS5 beats vector DBs for the symbol-graph workload, and where CodeGraph’s abstraction leaks.
- This post (2026-06-15) — Layer 3: model orchestration. The advisor strategy as the third recursion of the cost-curve frame, validated by Anthropic’s product, Tobi Lutke’s experiment, and HazyResearch’s academic version.
Read as one argument: the same cost-curve frame applies at three layers of agent architecture. At each layer, the correct design separates “bulk operations” from “decision operations” and pays only the cost each operation class requires. The five posts are five different applications of one frame, each cross-checked against fresh data as the productized announcements landed — the frame held up because it was built from the same shipped source those announcements describe.
Read as a toolkit: if you’re designing or evaluating agent architectures, the question to ask at every layer is the same. What’s the cost distribution of operations at this layer? Is there a “bulk vs. decision” split? Can the bulk path use a cheaper tool? Does the expensive tool only need to be on the decision path? Apply at retrieval (grep vs. RAG), storage (FTS5 vs. vector), model orchestration (executor vs. advisor). The next layer the frame will apply to is plausibly memory consolidation (cheap distillation vs. expensive synthesis) — that’s a future post topic if the pattern shows up.
A note on L2 iterating fast — between when this mini-series started (B published 2026-05-25) and when D publishes (2026-06-15), the LLM-symbol-graph layer kept moving: CodeGraph shipped point releases, and more tools in the same class are arriving. They all hit the same six conditions for a viable LLM-symbol-graph that the framework predicted; where they differ is inside the ranking layer — how each one orders the symbols a query surfaces (keyword + heuristics, graph-walk propagation, embedding re-rank, whatever comes next). The six conditions are about what’s required for an LLM-symbol-graph to exist at all; the ranking algorithm is the secondary design space within the framework, and it’s where the next tool will try to win. The empirical read of CodeGraph on a repo its team didn’t choose is in the companion benchmark post; the first-principles architectural read is in the companion Lab post. L2 keeps iterating; the framework is what’s stable.
Three threads converged on the advisor strategy because the cost-curve frame produced it independently each time. The frame is the durable insight; the architecture is the frame instantiated at one layer. Reading the source code, watching the productization, and modeling the convergence each contribute to the same picture.
If you build agents and are paying frontier-model rates for tokens that don’t need them, the advisor strategy is the practical fix. If you read agents and want a frame for evaluating what comes next, the cost-curve recursion is the lens. The series ends here, five posts and three layers in.
Companion piece 1: Agent Retrieval Is a Cost Curve Problem: Why Claude Code Doesn’t Use RAG Companion piece 2: Agent Memory Is a Cache Coherence Problem Empirical pair (Operator track): I Tested CodeGraph on Hono. The Tool-Call Savings Reproduce — the Cost Savings Don’t. First-principles companion: Agent Retrieval Above the Crossover: A First-Principles Read of CodeGraph Background: Consistency in Distributed Systems: Scenarios, Trade-offs, and What Actually Works Anthropic advisor strategy blog (2026-04-09): “The advisor strategy: Give agents an intelligence boost” HazyResearch Minions paper: https://arxiv.org/abs/2512.21720 pi-lifeline (open-source escalation extension inspired by Tobi Lutke): https://github.com/robzolkos/pi-lifeline
🎧 More Ways to Consume This Content
I occasionally advise small teams on backend reliability, Go performance, and production AI systems. Learn more: /services
Comments
This space is waiting for your voice.
Comments will be supported shortly. Stay connected for updates!
This section will display user comments from various platforms like X, Reddit, YouTube, and more. Comments will be curated for quality and relevance.
Have questions? Reach out through:
Want to see your comment featured? Mention us on X or tag us on Reddit.