
The 90% Problem: Why Most AI Agents Are Still Broken
Building an AI agent that works is easy. Building one that doesn't break is 90% of the work. Here's what that 90% actually looks like — from leaked source code and production A/B data.
Table of Contents
Your Agent Works Great. Until It Doesn’t.
You built an AI agent over the weekend. It calls tools, remembers context, follows instructions. You demo it to your team. Everyone’s impressed.
Monday morning, a user types “rename Ember to Infernia.” Your agent loops 15 times, burns through your API budget, and returns a response that doesn’t contain the word “Infernia.” A rename. One entity. One operation.
I’ve been there. I ran an eval suite on a production agent — 5 test cases, 5 runs each. Pass rate: 40%. Not on hard tasks. On things like “update the right character out of six” and “rename one entity.” The model was GPT-4 class. Plenty capable. The problem was everything around the model.
This is the 90% problem:
Building the core loop (perceive → reason → act): 10% of the work
Making it not break in production: 90% of the work
It took me a while to see where the problem actually was. The real gap wasn’t missing features. It was open loops: verification that doesn’t retry, memory that doesn’t decay, compression that doesn’t circuit-break.
Here’s what I found — from analyzing Claude Code’s leaked source, where a 1,729-line query.ts file contains a 1,421-line while(true) loop inside a roughly 512,000-line codebase, and from fixing a production agent’s pass rate with code changes alone. No model upgrade. No prompt magic. Just engineering.
The Five Pillars — And Where Agents Actually Fail
Every production agent needs five things. Most only build two of them well.
| Pillar | What It Does | Who Does the Work | Most Agents’ Status |
|---|---|---|---|
| Context Management | What the LLM sees | Code orchestrates; LLM helps compress | Dump everything, hope for the best |
| Memory Management | What persists across sessions | Code orchestrates; LLM helps recall | Basic store/retrieve, no lifecycle |
| Reflection | Agent checks its own output | Code triggers; LLM judges | Not implemented or logs-only |
| Planning | Agent thinks before acting | LLM (decompose tasks, sequence steps) | Decent — LLMs are good at this |
| Tool Use | Agent interacts with the world | LLM selects, Code executes | Decent — most mature pillar |
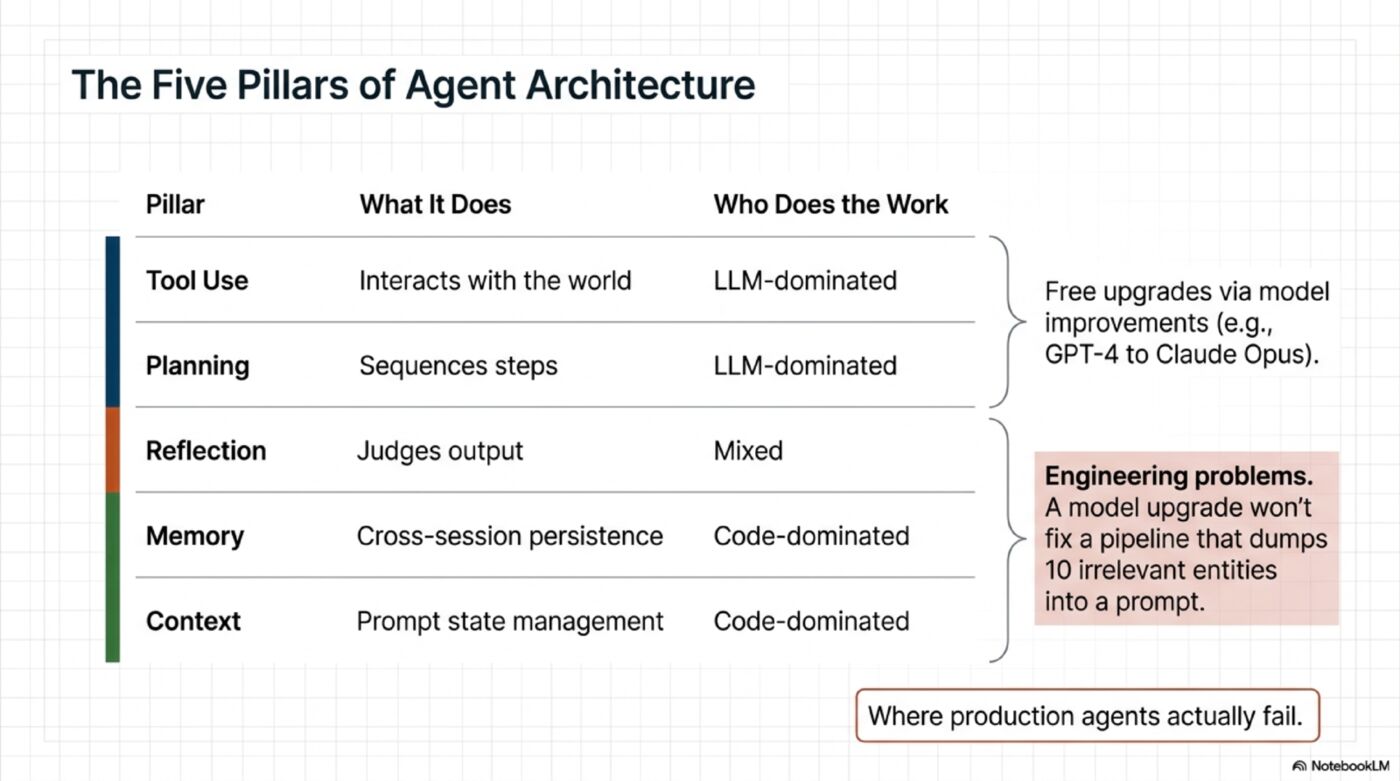
Planning and Tool Use work reasonably well because they ride on model improvements. GPT-3.5 struggled with tool calling; Claude Opus 4.6 is reliable. You get these improvements for free with model upgrades.
Context and Memory are where agents fail because they’re engineering problems, not model problems. Reflection sits in the middle: the LLM can judge quality, but code still has to trigger that check, route the result, and do something with it. No model upgrade will fix a context pipeline that dumps 10 irrelevant entities into the prompt.
The LLM vs Code Divide
This is the most important insight for anyone building agents:
HIGH LLM dependence (improves with better models):
Planning → LLM generates the plan
Reflection → LLM evaluates quality
Tool Selection → LLM picks the right tool
LOW LLM dependence (never improves from model upgrades):
Context Management → Code sorts, filters, compresses
Memory Management → Code stores, retrieves, scores, decays
Error Handling → Code classifies errors, retries, circuit-breaks
Tool Execution → Code runs tools, parallelizes, batches
State Management → Code tracks progress, checkpoints
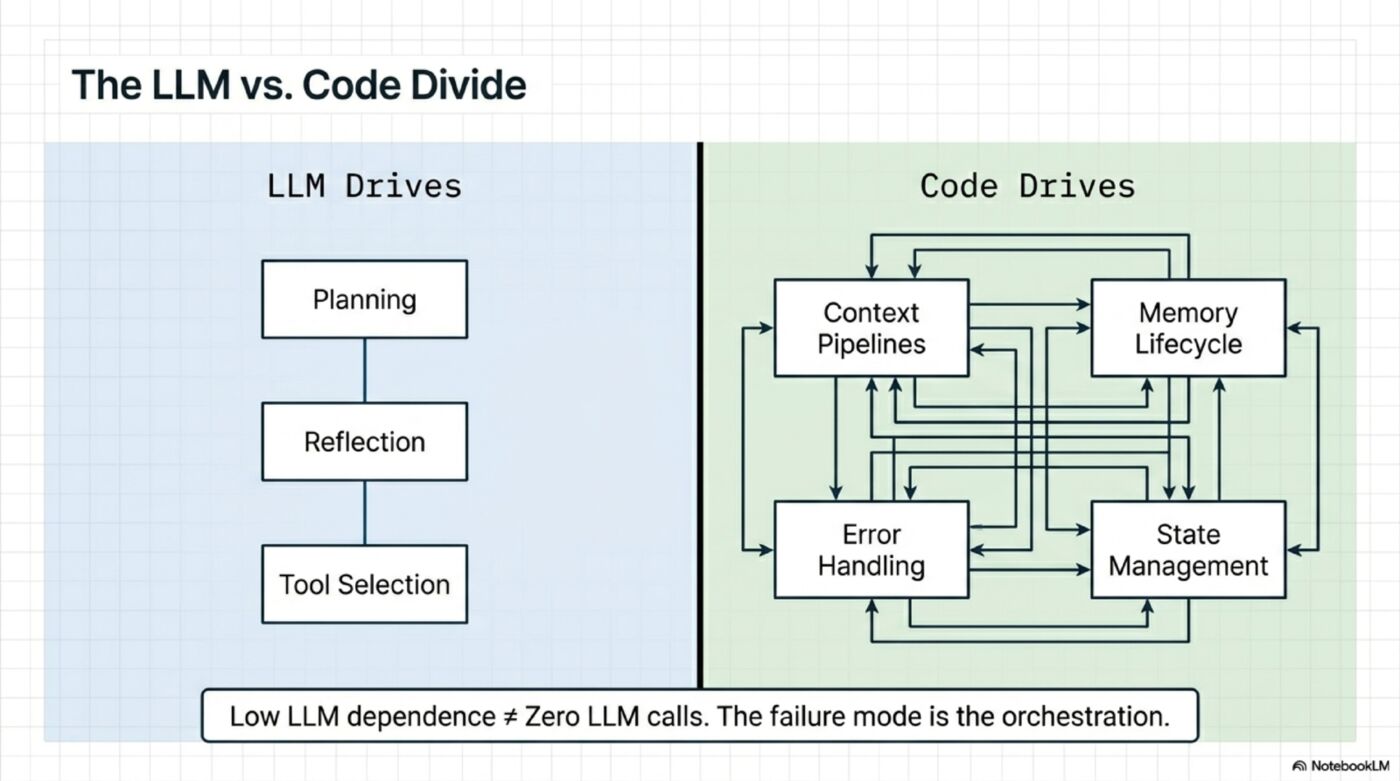
But low LLM dependence does not mean zero model calls. It means the failure mode is mostly in the orchestration. Even code-dominated pillars still use models in three very different ways:
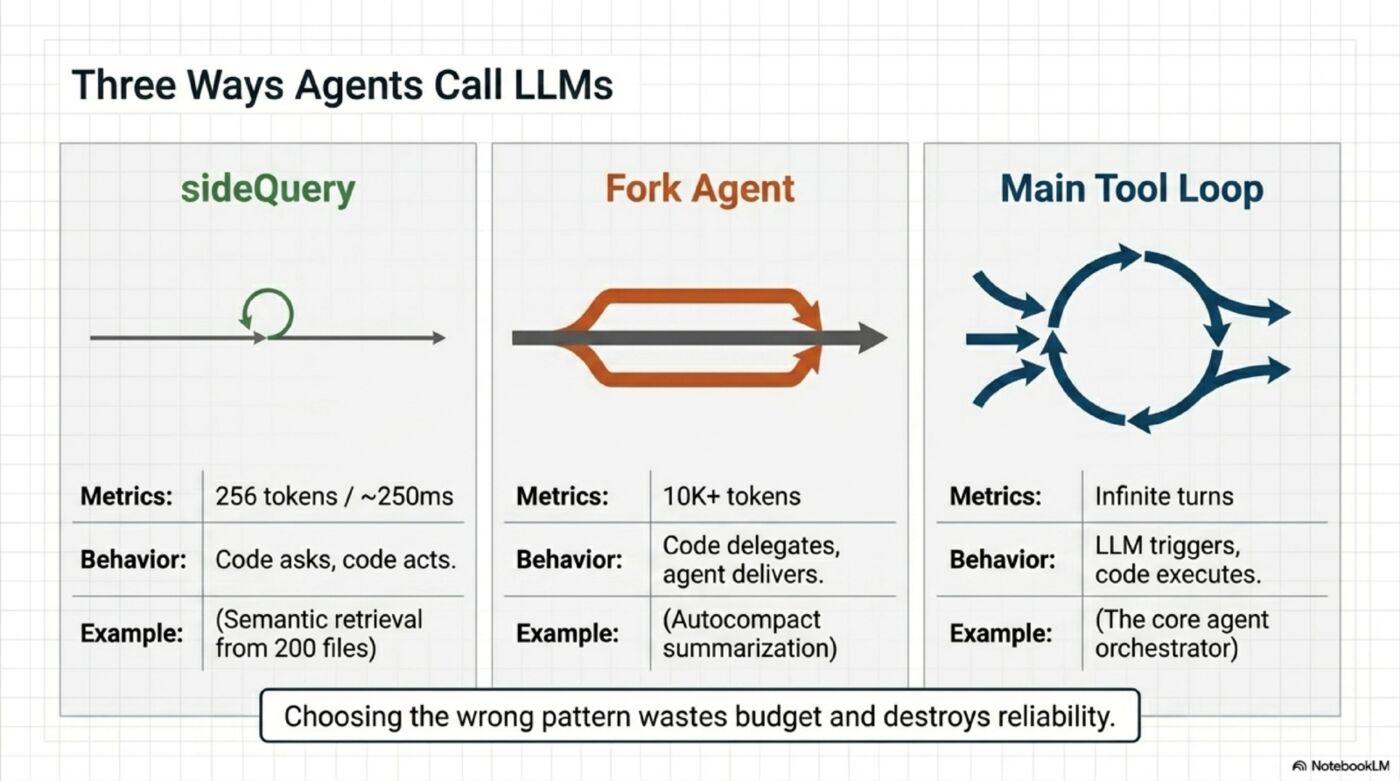
1. Direct LLM call (sideQuery) — Code asks a narrow question, takes the answer, and moves on. Example: Claude Code’s memory recall uses a single Sonnet side-query to choose 5 relevant memories from roughly 200 files.
2. Forked sub-agent — Code delegates a bounded task to a child agent with its own context, tools, and loop. Example: Claude Code’s autocompact hands summarization to a child agent instead of forcing the main loop to do it inline.
3. Tool-use loop — The LLM decides which tool to call, the program executes it, and the result flows back into the next turn. This is the main agent loop.
Simple question (which memories are relevant?) → Direct call
Complex but bounded task (summarize this) → Forked sub-agent
Open-ended execution (build this feature) → Tool-use loop
This choice is not academic. It changes latency, token cost, and failure modes. In Claude Code’s memory system, a side-query is cheap. A forked summarizer is much heavier. Using the wrong pattern wastes budget or hurts reliability.
The trap: Teams chase model upgrades (“let’s switch to Claude Opus”) instead of fixing their context pipeline. Better models help — but in my experience, fixing the context pipeline delivers a larger improvement per dollar than upgrading the model.
In one production system, fixing context management alone — without changing the model — moved quality from 40% to 60%. Seven out of eight fixes were pure code, zero LLM cost. The model was always capable. The context was holding it back.
What 90% Actually Looks Like — From Claude Code’s Source
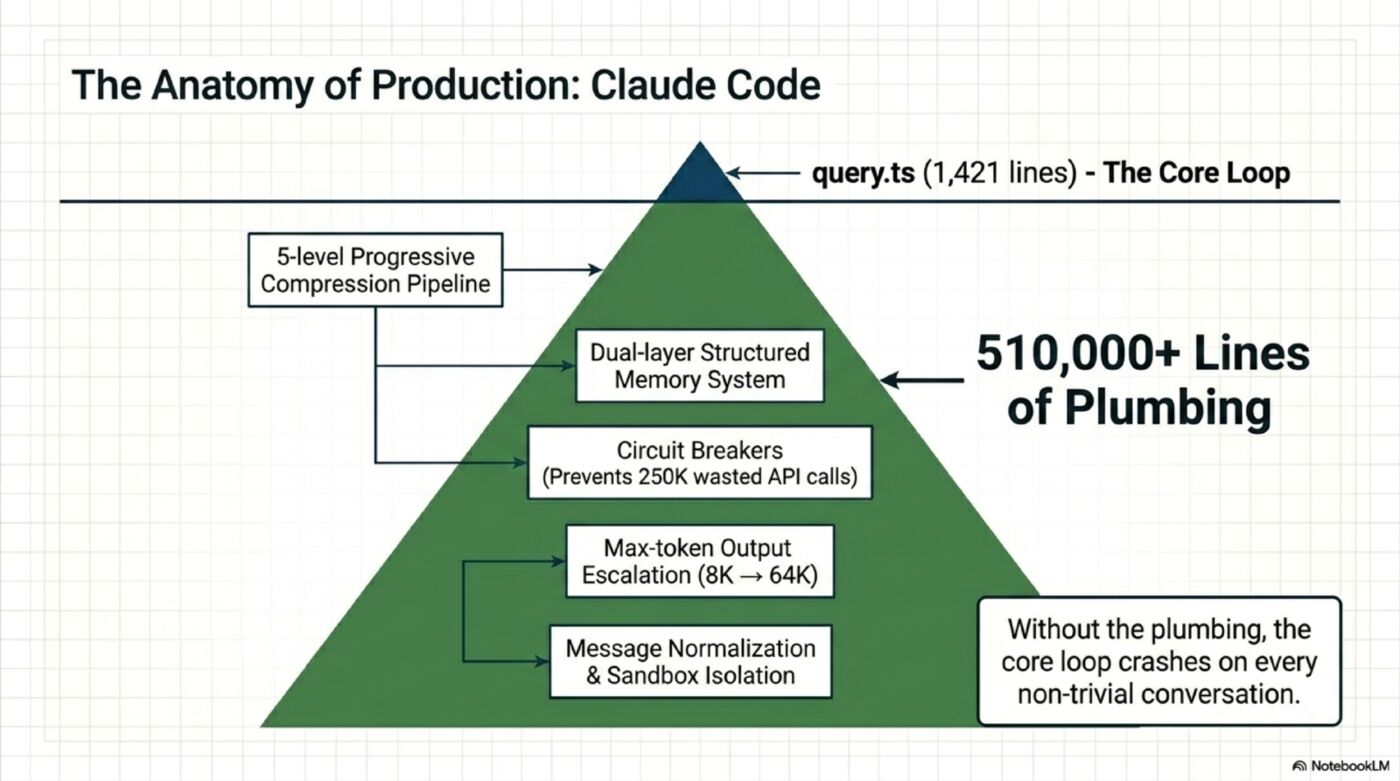
Claude Code’s leaked source is roughly 512,000 lines. Here’s the useful way to think about that split:
query.ts orchestrator file: 1,729 lines (~0.3%)
Core while(true) loop inside it: 1,421 lines
Everything else: ~510,000 lines (~99.7%)
That “everything else” is the 90%:
Context Management (3,960 lines in src/services/compact/):
- 5-level progressive compression pipeline
- Microcompact with dual code paths based on cache state
- Token estimation without API calls (<5% error)
- Post-compression recovery (restore last 5 files, skills, agent state)
- Circuit breaker: 3 consecutive failures → stop (after 250K API calls/day were wasted without it)
Memory System (1,736 lines in src/memdir/):
- 4-type closed taxonomy with structured frontmatter
- Sonnet side-query for semantic retrieval (250ms, async prefetch)
- Background extraction agent with mutual exclusion
- Trust verification (eval went 0/2 → 3/3 with this addition)
Error Handling (spread across entire codebase):
- Message normalization: fix orphan tool_use/tool_result pairs from crashes
- Prompt-Too-Long recovery: reactive compression as last resort
- Tool failure classification: timeout vs permission vs not-found
- Max output token escalation: 8K default → 64K on truncation
Permission System (multi-layer):
- Tool-level risk classification
- User confirmation for dangerous operations
- Sandbox isolation for high-risk tools
- Context injection scanning
None of this is intellectually exciting. It’s plumbing. But without it, the “exciting” part — the agent loop — crashes on every non-trivial conversation.
OpenClaw and Hermes Surface the Same Pattern
Two open-source agents worth watching right now — OpenClaw and Hermes Agent — illustrate the same architectural lesson.
OpenClaw:
- Context management: still basic; I don’t see the kind of progressive compression Claude Code built
- Memory: Markdown + SQLite (more sophisticated than Claude Code’s storage layer)
- Reflection: limited; I don’t yet see a strong closed verification loop
- Security: public reports in early 2026 highlighted exposed instances and malicious marketplace skills;
openclaw security auditexists, but tools alone don’t close the operational loop
Hermes Agent:
- Context management: still basic
- Memory: SQLite + full-text search +
MEMORY.mddual-layer - Reflection: self-evolving skills generated from completed tasks
- Error handling: layered on paper, but still early
- Maturity: promising, but I haven’t seen evidence yet that the self-iteration loop holds up at scale
Both can complete tasks. My point is not that they don’t work. It’s that the hardest production loops — compression, failure accounting, verification retries, and memory hygiene — still look only partially closed. The features exist; the loops aren’t closed.
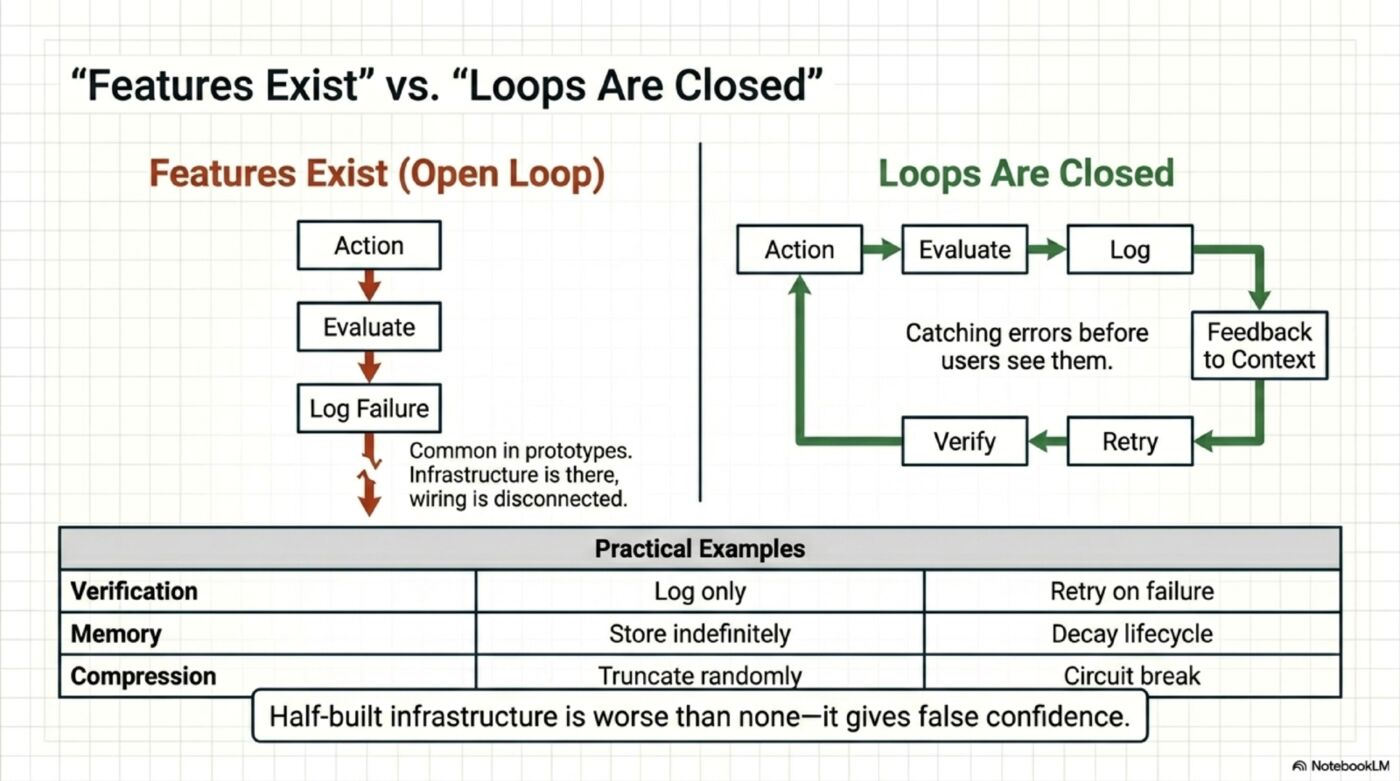
“Features Exist” vs “Loops Are Closed”
This is the most overlooked distinction in agent architecture:
Open loop: Build a verification step → log issues → done
Closed loop: Build a verification step → log issues → retry with feedback → verify again
Open loop: Score memory relevance → store the score → done
Closed loop: Score memory relevance → reinforce high-scoring memories → decay low-scoring → improve retrieval over time
Open loop: Detect compression failure → log it → continue
Closed loop: Detect compression failure → count consecutive failures → circuit-break after 3
In every open-source agent I’ve analyzed so far, some of the critical loops are still open. The infrastructure is there. The wiring is only partially connected.
Here’s the test: look at your agent’s verification step. Does it log a failure and move on? That’s an open loop. Does it log, retry with the failure as feedback, and verify again? That’s closed. The difference is one if statement and a retry call — but it’s the difference between “we have quality checks” and “we actually catch errors before users see them.”
This is the hardest 10% of the 90%. Not building the infrastructure — connecting it.
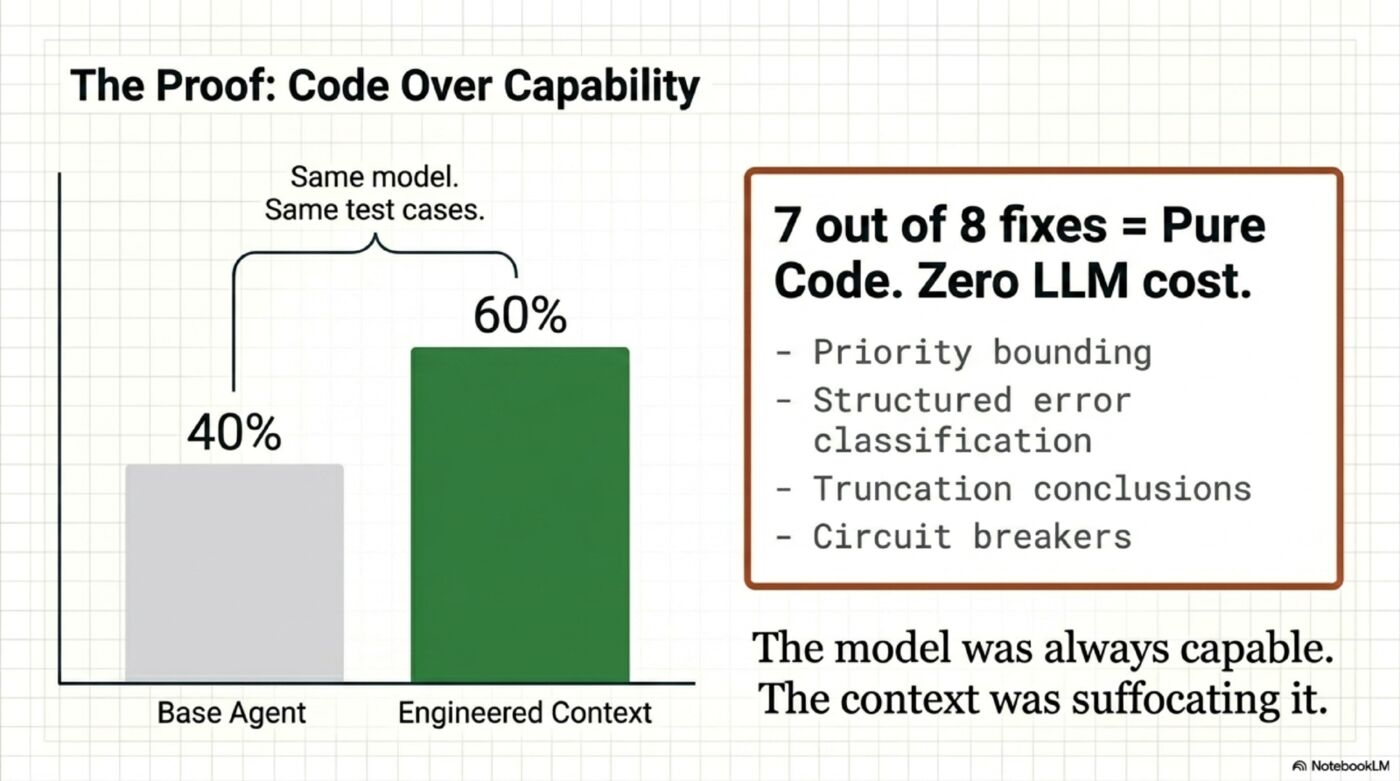
The Proof: 40% to 60% With Code Alone
I ran A/B evals on a production agent. Same model, same test cases, different code. Result: 40% → 60% pass rate.
The breakdown: 8 fixes total. 7 were pure code — zero LLM cost. Context prioritization, structured error classification, round limits, conclusion preservation during truncation, circuit breakers. The only fix that used an LLM call was a pre-loop planning step at $0.003 per request.
The model was always capable. The context was holding it back.
(Full case study with per-test breakdown: How I Improved an AI Agent from 40% to 60%)
What This Means for Builders
If you’re building an AI agent:
Don’t start with the model. Start with context management. Clean, prioritized, bounded input is the highest-leverage investment you can make.
Close your loops. If you built a verification step, make it retry. If you built memory scoring, wire the reinforcement. Half-built infrastructure is worse than none — it gives false confidence.
Measure before you upgrade. Before switching to a more expensive model, run an eval suite on your current one. The bottleneck is probably context, not capability.
Budget 90% of your time for the 90%. The agent loop is a weekend project. Error handling, compression, memory lifecycle, permission systems — that’s the real work. Plan accordingly.
The model is a commodity. The engineering around it is the product.
Ask yourself: what percentage of your agent’s codebase is the core loop, and what percentage is everything else? If you don’t know the answer, that’s where to start.
Diagrams from this essay packaged as a single-file reference: Engineering Reliable Agents (PDF).
Part of the AI Agent Architecture series.
Deep dives into the 90%:
- Claude Code Part 3: The 5-Level Compression Pipeline — how Anthropic solved context management
- Claude Code Part 4: Why Markdown Instead of Vector DBs — first-principles memory tradeoffs
- 40% to 60% With A/B Data — the full case study behind the numbers in this article
🎧 More Ways to Consume This Content
I occasionally advise small teams on backend reliability, Go performance, and production AI systems. Learn more: /services
Comments
This space is waiting for your voice.
Comments will be supported shortly. Stay connected for updates!
This section will display user comments from various platforms like X, Reddit, YouTube, and more. Comments will be curated for quality and relevance.
Have questions? Reach out through:
Want to see your comment featured? Mention us on X or tag us on Reddit.