AI Operator track — production AI agent engineering. Validation loops, tool-call reliability, completion ownership, context engineering, cost forensics, and observability for systems that ship and stay shipped.
Long-form writing and video on production AI agent engineering — the 90% of work that happens after the model gives you a demo that works.
Topics: validation loops, tool-call completion ownership, context engineering, retry budgets, cost forensics, and observability for systems that ship and stay shipped.
Companion to the Harrison AI Operator YouTube channel. Blog and video are listed below — most recent first.
Blog
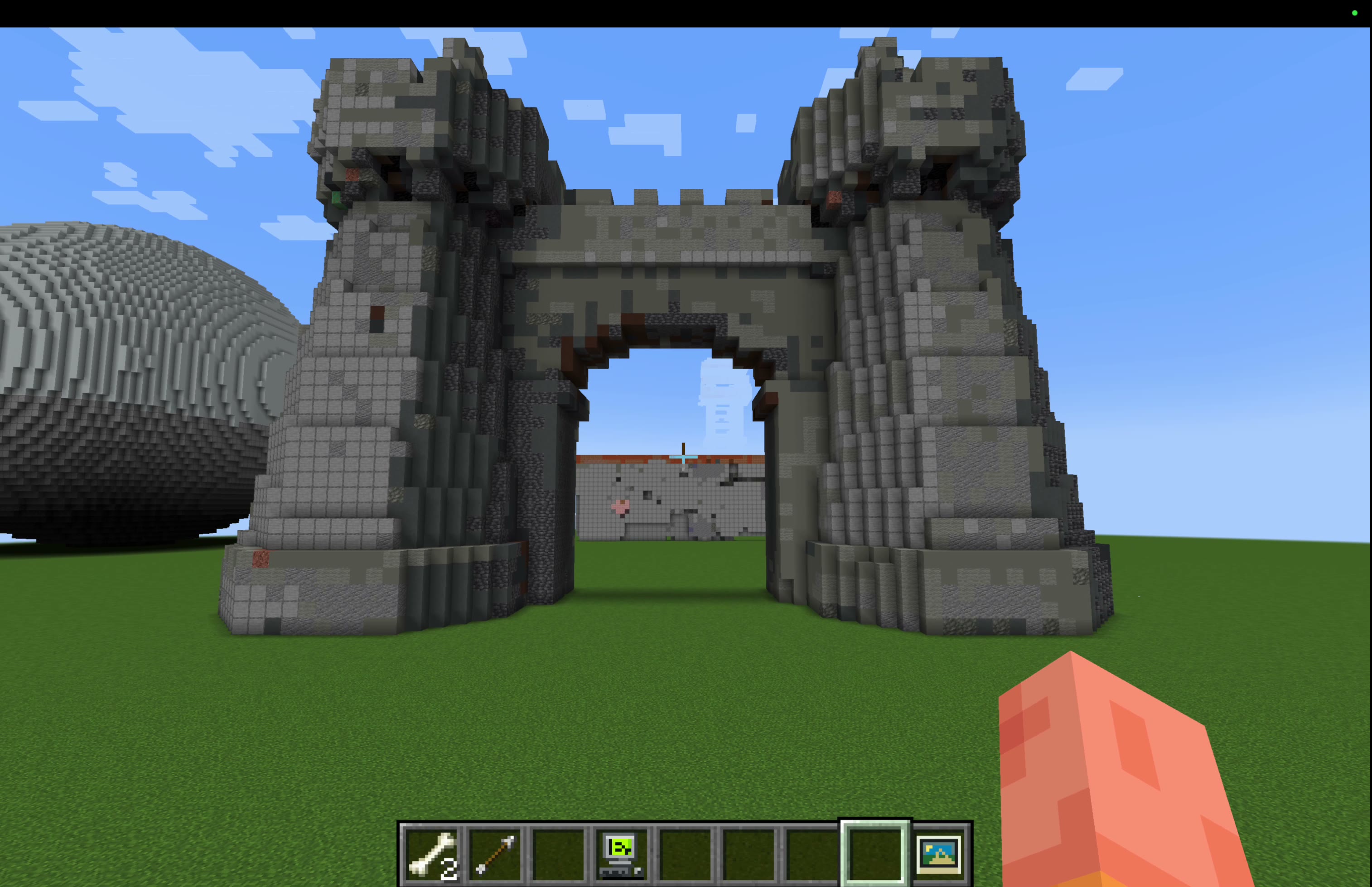
I ran eight building prompts through Higgsfield's Minecraft prompt-to-build. It nails single shapes in a minute but drops exact sizes, materials, doors, and whole scenes.
2026-06-18
11 min read
Blog
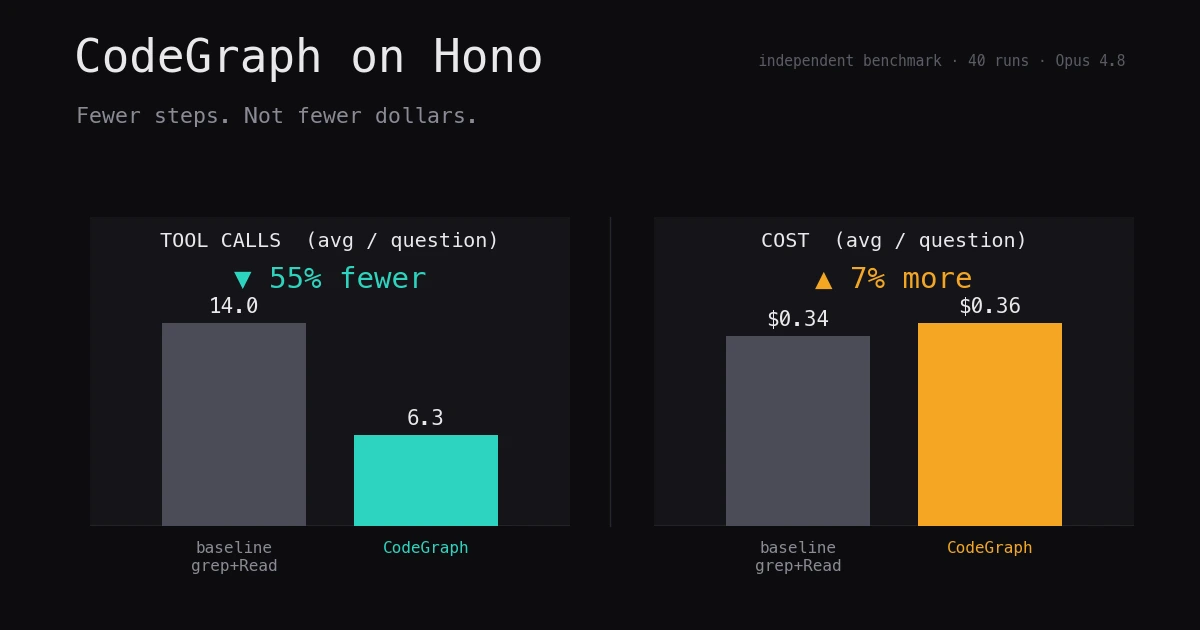
Independent CodeGraph benchmark on Hono (~280 TS files): -55% tool calls reproduces the published claim, but cost is a wash (+7%), not -35%. Raw CSV included.
2026-06-01
19 min read
Blog

Same model, same test cases, 20% better results. 7 out of 8 fixes were pure code, zero LLM cost. Here's exactly what I changed and why it worked.
2026-05-12
7 min read
Blog

Don't bind to a single AI. Run three in competition, make the final call yourself, and let results judge everyone. The operating model for staying valuable in the AI age.
2026-05-03
10 min read
Video
Your AI agent probably isn't failing because the model is weak. It's failing because you're fixing the wrong layer. The other 90% — context, memory, validation — is where production breaks.
2026-04-20
Video

Building an AI agent that works is easy. Building one that keeps working is where most teams fail. Long-form breakdown of the four-layer failure model.
2026-04-18
Blog

Building an AI agent that works is easy. Building one that doesn't break is 90% of the work. Here's what that 90% actually looks like — from leaked source code and production A/B data.
2026-04-17
9 min read
Blog

How to use OpenAI's Codex plugin inside Claude Code — turning Claude Opus and GPT-5.4 into a dual-brain coding system. Setup, commands, rescue workflows, and when each brain wins.
2026-04-07
6 min read
Blog

Claude Code's memory system looks simple on purpose. This piece breaks down the tradeoffs behind Markdown memories, Sonnet side-queries, and the decision to avoid vector databases.
2026-04-05
10 min read
Blog
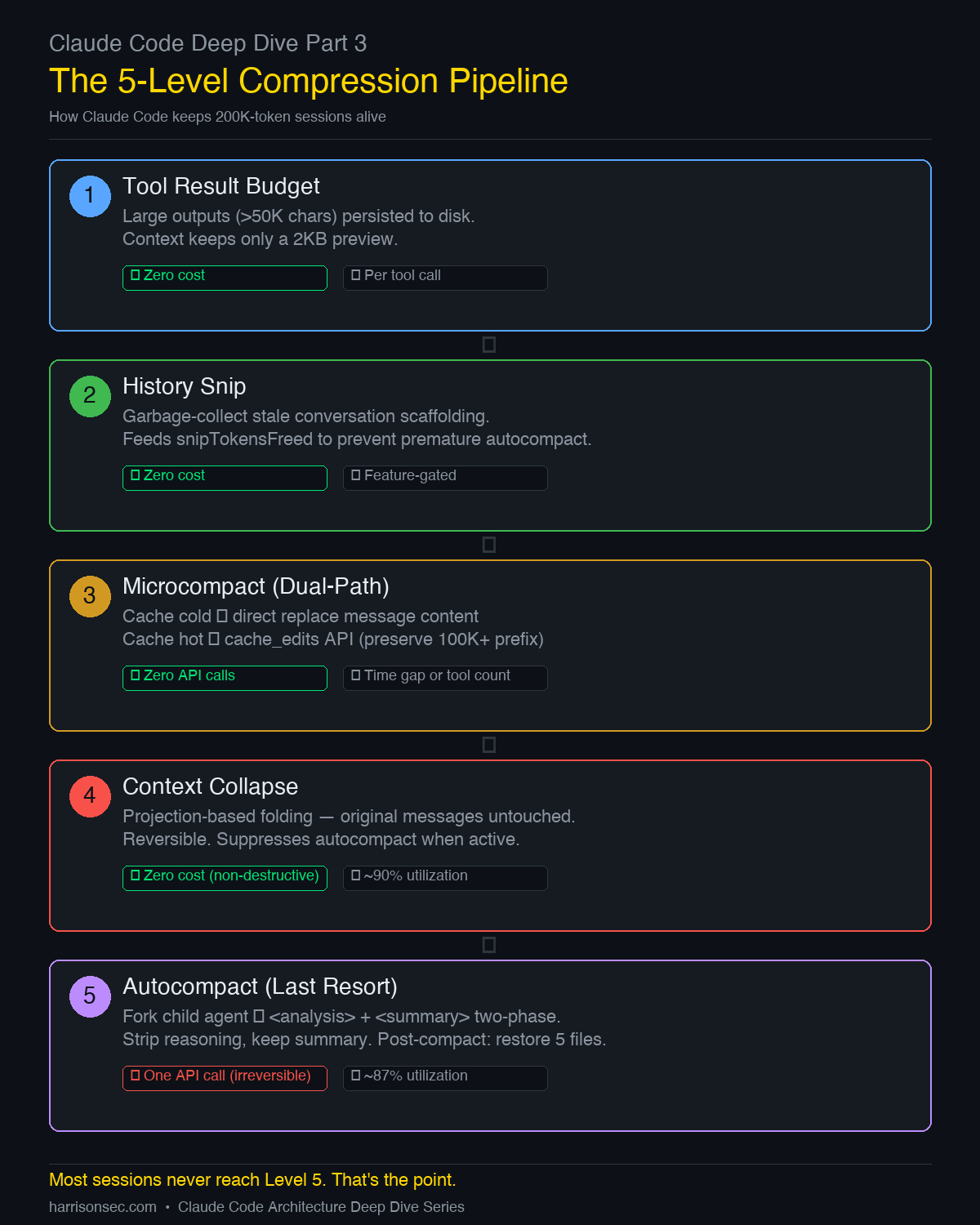
How Claude Code's context compression pipeline survives 1M-token sessions: 5 levels of progressive compression, dual-path algorithm, source walk-through.
2026-04-04
9 min read